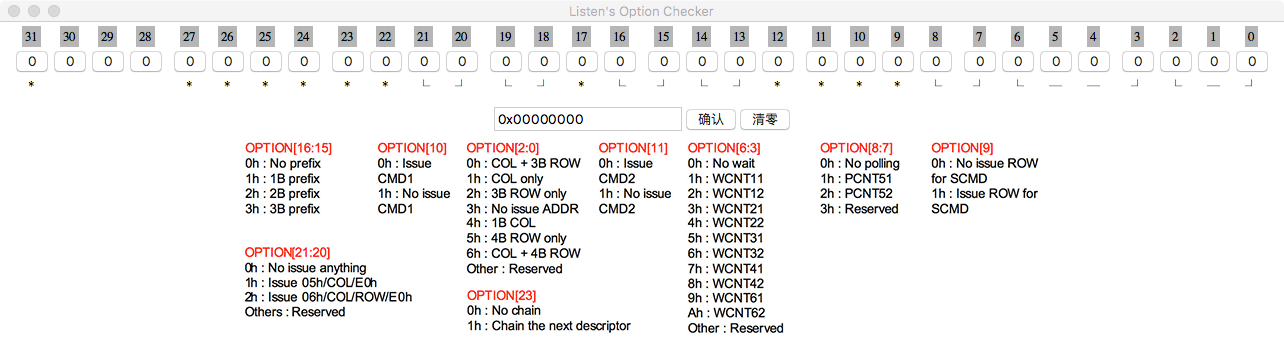
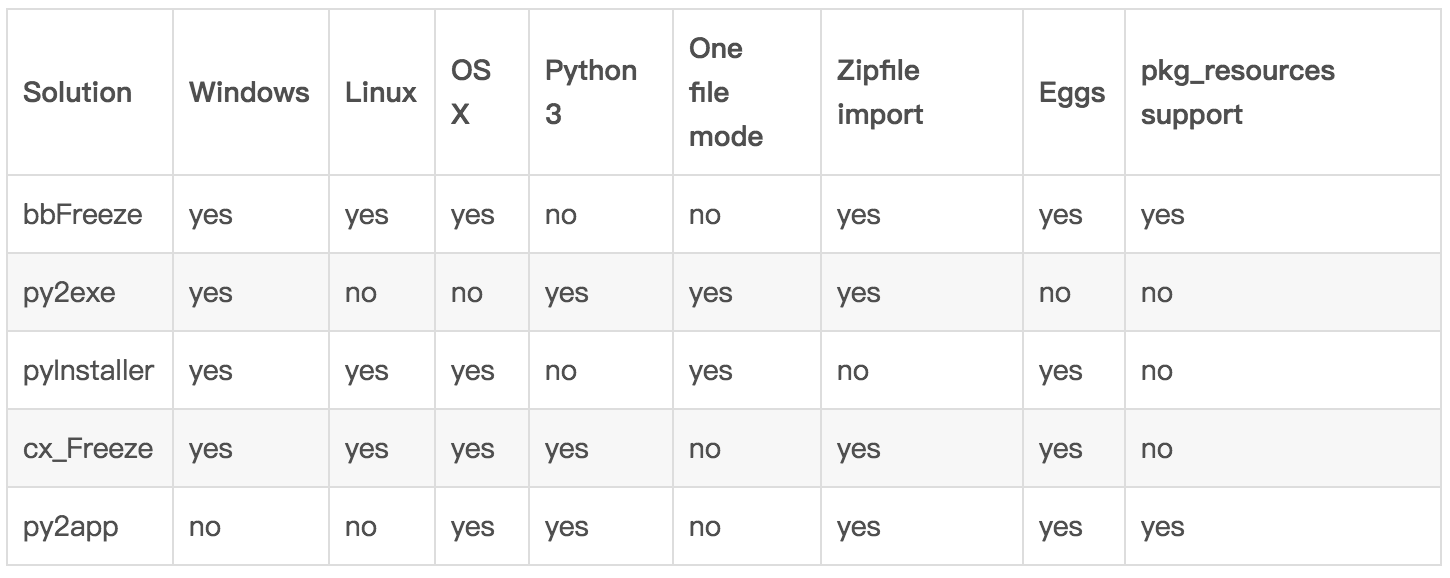
有段时间没写这种文章了。根据姜文电影的名场面,我决定将博客的这个栏目命名为——「正经人谁写日记呀」,哈哈。
2019年像之前的每一年一样,过得很快。对它的印象只剩加班加班、辞职家里蹲、旅行,然后,就是现在:手机在放歌,我坐在床上,敲打老旧的 MacBook,现在是 12.31 02:02。
又是不太长进的一年。原本没有值得写的东西。但今年有两个瞬间让我想写点什么:
一是前女友在微信上再次联络我之后,我觉得人和人也许是可以相互原谅的,心里稍微好受一点,当时感激地有写东西的冲动。
二是前几天,见了一些老朋友。看到大家都过得很好,也许说不上很好但也是「稳步前行」。似乎让我对自己也稍稍有了一点信心。
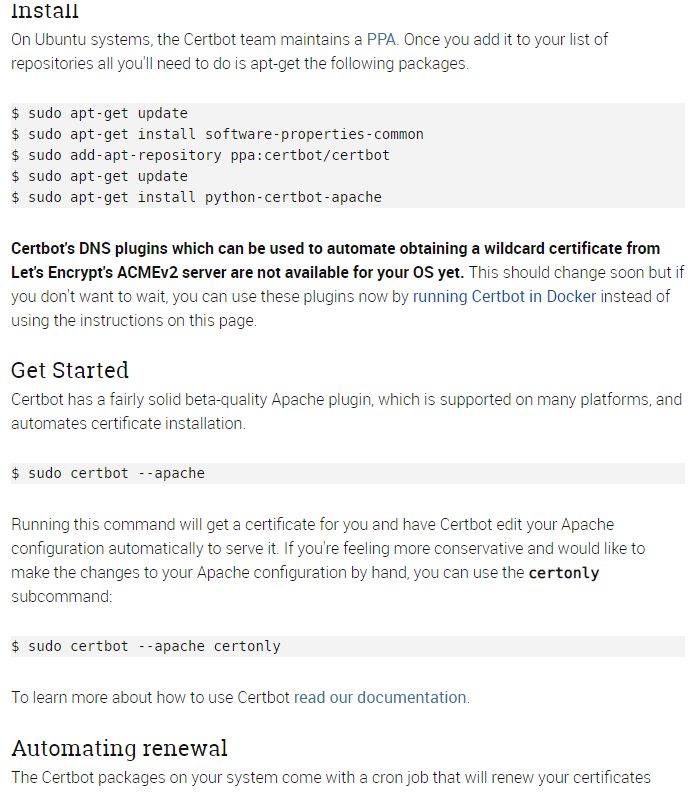 不一定跟我一样,选择你自己的操作系统和服务器软件,certbot 页面上会提供对应的安装方法。
安装后继续按照 certbot 页面的说明 get start ,程序的交互式界面会引导你进行选择和配置。
跟随引导进行操作,完成后网站就被 Let’s Encrypt 提供的 SSL/TLS 证书保护起来了。是不是很有安全感!
不一定跟我一样,选择你自己的操作系统和服务器软件,certbot 页面上会提供对应的安装方法。
安装后继续按照 certbot 页面的说明 get start ,程序的交互式界面会引导你进行选择和配置。
跟随引导进行操作,完成后网站就被 Let’s Encrypt 提供的 SSL/TLS 证书保护起来了。是不是很有安全感!





 是一个关于
是一个关于 的函数,所以目标是求一组最优的
的函数,所以目标是求一组最优的
 是一个矩阵,
是一个矩阵, 是列向量,
是列向量, 行其实就是
行其实就是  这样的一组特征(feature),其中的每个值都可以视作特征空间里的一个维度。
这样的一组特征(feature),其中的每个值都可以视作特征空间里的一个维度。 ,总共
,总共 个样本结果组成了向量
个样本结果组成了向量 与真实结果
与真实结果
![\[ \begin{cases} \frac{\partial J}{\partial \theta_1} = \frac{1}{m} (h_\theta(x^1)-y^1) x_1\\ \frac{\partial J}{\partial \theta_2} = \frac{1}{m} (h_\theta(x^2)-y^2) x_2\\ \dots \\ \frac{\partial J}{\partial \theta_n} = \frac{1}{m} (h_\theta(x^n)-y^n) x_n \end{cases} \]](https://www.twisted-meadows.com/wp-content/ql-cache/quicklatex.com-f9b6d356c7a24a2620e66f9856fdf47a_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{cases} \frac{1}{m} (h_\theta(x^1)-y^1) x_1 = 0\\ \frac{1}{m} (h_\theta(x^2)-y^2) x_2 = 0\\ \dots \\ \frac{1}{m} (h_\theta(x^n)-y^n) x_n = 0 \end{cases} \]](https://www.twisted-meadows.com/wp-content/ql-cache/quicklatex.com-b0229cf18f354e08a97a5d8f64c9482b_l3.png "Rendered by QuickLaTeX.com")

![\[ J = (\overrightarrow{y} - \mathbf{X}\theta)^\top (\overrightarrow{y} - \mathbf{X}\theta) \]](https://www.twisted-meadows.com/wp-content/ql-cache/quicklatex.com-dcb899a14aaed2b0c782b42f8c28751f_l3.png "Rendered by QuickLaTeX.com")
![\[ best \theta = (\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top \overrightarrow{y} \]](https://www.twisted-meadows.com/wp-content/ql-cache/quicklatex.com-8fb330dc98784e20bd1c08fce76a01a6_l3.png "Rendered by QuickLaTeX.com")
 个特征维度的
个特征维度的  ,而 Gradient Descent 的复杂度为
,而 Gradient Descent 的复杂度为 
 时,才开始考虑使用 Gradient Descent 。
时,才开始考虑使用 Gradient Descent 。 ,意味着括号内的矩阵必须是可逆的。
,意味着括号内的矩阵必须是可逆的。 不可逆时的一种传统的处理方式,可以用的原因是广义逆得出的
不可逆时的一种传统的处理方式,可以用的原因是广义逆得出的