今年初,有感于微信公众号平台删帖效率,打算写一个自动检查文章是否被删的机器人。
并不想弄成爬虫,只想关注我和小伙伴们所接触的领域里的信息审查状况。就把它设计成了「被动接受观察目标,定期观察和备份文章,检查到文章失效通知登记者」的系统。
之前简单介绍过Tkinter:Python 可视化图形界面简单实践
这次来记点进阶心得。
Tkinter实现标签页效果
用 Python 和 Tkinter 写过一些小工具。现在想把它们整合到一起,以类似“标签页”的形式来切换。

具体参考:Tkinter 8.5 reference: a GUI for Python
用到的是 Notebook 控件,这方面网上比较少提,所以记录一下。
举例:
MyNotebook1 = Notebook(top)
MyNotebook1.place(relx=0.022, rely=0.062, relwidth=0.956, relheight=0.876)之后你就可以将 Notebook 作为 parent 来构建 Frame,承载你的标签页:
Tab1 = Frame(MyNotebook1)
....
MyNotebook1.add(Tab1, text='First tab name')与普通的 Frame 不同,完成构建的 Tab1 不是通过 pack、grid、place 来布局,而是用 Notebook 的 add 方法,并指定标签名。
再来一个例子:
#about tab
self.TabX = Frame(self.Notebook1)
self.TabXLbl = Label(self.TabX, text="Listen's Swiss Army knife")
self.TabXLbl.pack()
self.TabXLb2 = Label(self.TabX, text="ver 1.3.0")
self.TabXLb2.pack()
self.Notebook1.add(self.TabX, text='About')
#about tab end上面这个标签页实际效果大致是:
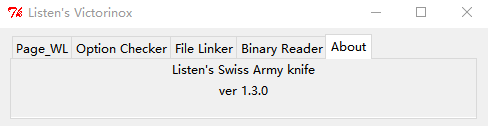
简单来说,你只要先建立了 Notebook 控件,然后往里面 add Frame 就行了,每个 Frame 都会呈现为1个独立的标签页,名字在 add 时指定。
GUI 界面与逻辑分离
如果只是一个功能简单的小工具,随便怎么写都没问题。但我在把多个小工具整合成一套时发现,东西一多了会很难管理。
在网上看到别人的做法,是将界面和逻辑分离开:
class Application_ui(Frame):
#这个类仅实现界面生成功能,具体事件处理代码在子类Application中。
def __init__(self, master=None):
Frame.__init__(self, master)
self.master.title("Listen's Victorinox")
self.master.geometry('880x380')
self.createWidgets()
def createWidgets(self):
....
class Application(Application_ui):
#这个类实现具体的事件处理回调函数。界面生成代码在Application_ui中。
def __init__(self, master=None):
Application_ui.__init__(self, master)
....上面的做法是从 TK 继承了 Frame,然后重写成自己的 UI (Application_ui)。这个 Application_ui 只生成界面,之后再用 Application 类去继承它,在 Application 里面进行逻辑处理。
单独调试 UI :
if __name__ == "__main__":
top = Tk()
Application_ui(top).mainloop()这样的好处是,在设计 UI 时,可以只考虑控件和布局。若画面呈现不如预期,就可以直接调整。
而 UI 里的每个控件其实都是空的,它们不实现任何功能,功能都在 Application 类里去添加。
例如:
self.Tab1varWL = StringVar()
self.Tab1varWL.set("WL")
self.TabStrip1__Tab1WLNum['textvariable'] = self.Tab1varWL
self.TabStrip1__Tab1WLNum.bind("Return",self.WL2Page)self.TabStrip1__Tab1WLNum 这个控件之前是空的,现在我给它设置了 StringVar() ,并且绑定了一个事件是
Return,这个控件收到回车键时会触发 self.WL2Page 方法。另一个 tab 的实例:
# Tab4 var
self.Tab4path = StringVar()
self.Tab4pathEntry['textvariable'] = self.Tab4path
self.Tab4ButtonSelect['command'] = self.Tab4selectPath
self.Tab4ButtonConfirm['command'] = self.Tab4ReadFile相比于把 GUI 各种按钮的函数摆得到处都是,现在则可以按tab分割,都放在 Application 类的私有方法里。
对这部分进行调试:
if __name__ == "__main__":
top = Tk()
Application(top).mainloop()开发时,可以先在 Application_ui 类里面调试界面,完成后,再到 Application 类给控件们分配变量、绑定方法,验证逻辑功能。
两部分工作分割开,这样就清晰很多。制作复杂界面的 GUI 程序时,界面和逻辑的分离很有必要。
将编译好的程序打包成安装程序来发布
我在上一篇Python 可视化图形界面简单实践里介绍过,用 pyinstaller 简单快速地打包 python 程序,生成不依赖 python 的可执行文件 exe。
当时有说 -F 参数是将程序打包成一个单独的exe文件,不加则会生成一整个目录的文件。 同时也因为速度原因不建议添加这个参数。
可是程序发布时,这么多零散的文件是很不方便的,你只能将目录压缩成zip、发给别人,让别人自己去找里面的 .exe 文件。
一个合理的发布方式是提供安装文件,收到的人执行安装文件就能完成部署。
这里我们用到的工具是 NSIS(Nullsoft Scriptable Install System)。具体步骤参照这篇教程,写的很详细,我就不搬过来了:程序打包成exe文件
原则上任何语言的程序都可以这样发布。NSIS用压缩算法把你的程序那一大堆文件压成一个包,套了个安装向导的壳。
用户拿到后一运行,安装向导像所有程序一样,引导他们选择安装路径等等,然后把压缩包解压到用户路径,再为这个路径创建桌面/开始菜单的快捷方式。
NSIS 可以提供不同语言的安装向导,你甚至可以给它添加奇怪的用户协议~
这篇文章涉及的内容都是我在开发 Victorinox 小工具时遇到的。这是一把全世界只对我1个人有用的瑞士军刀。。。。。。
源码已push到GitHub:https://github.com/MamaShip/Victorinox
最近工作上常用的一个操作需要进行二进制数bit翻转。由于不知道windows系统计算器就有这个功能,自己用python写了一个。简单记录下实践过程。
Python进行GUI编程,可用的库并不多。功能也不算强大,这篇文章简单列举了几个库的特点。
我呢,没有被它们任何一个吸引。所以直截了当地选择了Python标准库自带的Tkinter。
( Python Tkinter 官方文档:https://docs.python.org/2/library/tkinter.html )
完成品大致是这样的:
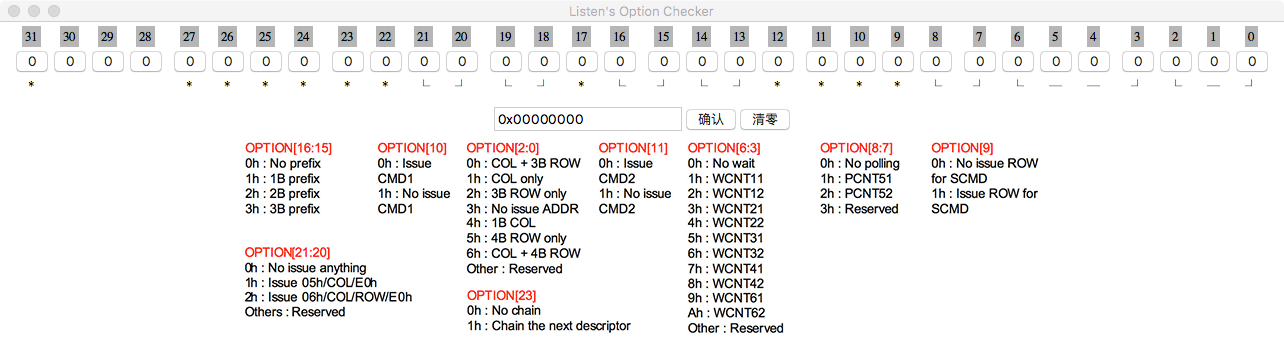
基本框架是:
from Tkinter import *
top = Tk()
top.title("Listen's Option Checker")
# Your code here
top.mainloop()在这个基础的窗口里,用Frame控件分割空间(类似于html和CSS那种方式)实现布局。
然后在各个分区的frame里,根据与用户的交互方式,选择对应的控件:Button、Entry、Label……
控件由类似这样的句子生成:
Confirm_Button = Button(frm2Sub1,text="确认",command=hex2bin)
Confirm_Button.pack(side=LEFT)第一句创建了一个Button实例,这个按钮的父容器是frm2Sub1,按钮上文字为「确认」,当用户按下这个按钮时,就会立即触发一个名为hex2bin的函数,来对用户的操作进行响应。
现在命名空间内的Confirm_Button指向了这个Button实例。用.pack()方法来完成对它的部署。参数side=LEFT是要让它在所属Frame容器内靠左放置,若不指定位置,每个新的控件都会被部署在前一个控件下方。
当然,包括Frame在内的所有控件都需要通过.pack()来呈现。如果漏了这一句,程序界面内就看不到对应控件。
去查一下Tkinter支持控件列表,再配合以上基本信息,已经足以制作一些功能极其简单的可视化程序界面。其实网络上大多数介绍文章也没有讲的更多。
但还有一些值得注意的地方。
Command传参
Button控件的command参数,是不允许传参的。
我理解此处的command参数就类似于一个函数指针,指向目标函数。
网上比较常见的传参方法是用lambda函数:
Button(frm, textvariable=strvar31, command = lambda : FlipBit(31,strvar31))它其实是定义了一个匿名函数,在Button被按下时执行的是lambda,再由lambda将参数交给你的执行函数。类似这样的用法,在只有一两个同类控件的时候是可行的。也很方便。
但对我这个程序来说,需要32个按钮充当32位二进制bit,不可能手动复制32个button的创建过程。
这里的Lambda函数,如果用在for循环创建的button内,就会导致它传进去的参数固定为for循环的控制变量i(的最大值,也就是最后一次循环的值)。
原因也很简单,lambda函数在未被执行时并不会被解释(编译成固定的函数)。它只有被真正执行时才生效。而真正执行时是Button按下时,不是For循环当初loop经过它时。所以i始终为定值(终值)。
最终的办法是用一个Event Handler。定义如下两个function:
def handler(bit):
num[bit] = num[bit] ^ 1
strvarlist[bit].set(str(num[bit]))
binary = "".join(map(str,num))
decimal = int(binary,2)
var16.set(hex(decimal))def handlerAdaptor(fun,v):
return lambda event, fun=fun, v=v: fun(v)由handlerAdaptor作中介,将参数传进去。方法是将handler与鼠标点击event绑定。
绑定鼠标事件的Button写法如下:
ButtonList.append(Button(SubSubFrameList[i], textvariable=strvarlist[i]))
ButtonList[i].bind('', handlerAdaptor(handler, i))
ButtonList[i].pack()这里跟前面创建控件的方式不同,有一个小变化:
为了使我们这32个bit的控件(包括button和其上的textvariable)可以被方便地遍历,我不再是给它们赋予一个固定的命名,而是将每个实例直接.append()到它们各自的list里。
这样我在另外的函数里处理它们时,可以直接用下标来控制和选择。——包括这里创建完成后的.bind()和.pack(),也都是用list加下标来做选择。
一些参考资料:
tkinter官方文档学习笔记
Tkinter 控件简单计算器示例
Python Tkinter参考资料之(通用控件属性)
tkinter模块常用参数(python3)
Python Tkinter GUI(三)显示图片
Python GUI进阶(ttk)—让界面变得更美
打包exe程序
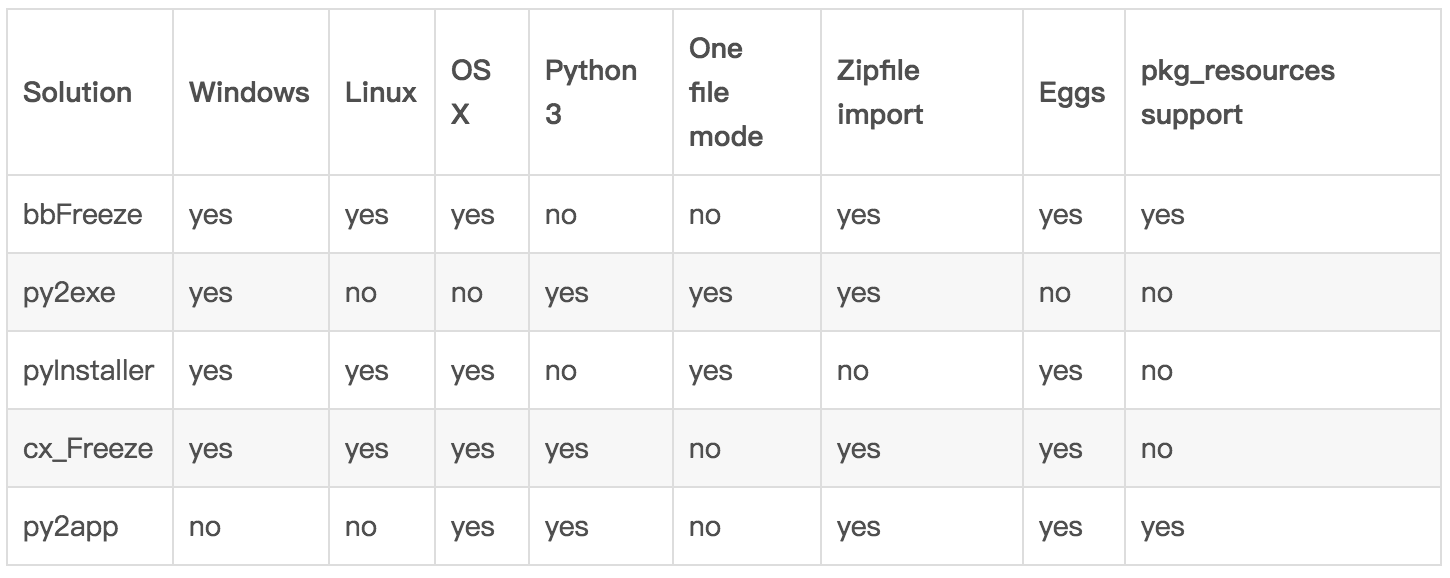
上表来自《Python程序打包成exe可执行文件》,文章很有用。我此前用过的py2exe不好用,这次选择pyinstaller,简单打包方法:
pyinstaller -F -w main.py生成文件在dist目录。build仅为中间文件。
-F 是打包成一个单独的exe文件,不加则会生成一整个目录的文件。(加了该参数会导致程序调用外部image失败,在spec配置内添加DATA也没用)
-w 不需要查看命令行时,用这个参数隐藏cmd画面。
亲测-F之后程序启动速度慢了几十倍不止。所以我不建议-F
更复杂的配置,需要使用脚本相同目录下,由pyinstaller生成的一个.spec文件。我没有深入研究,需要时可以在网上查。(参考:pyinstaller打包工具的使用说明、将自己的python程序打包成.exe/.app)
写了一个脚本实现自动化测试过程。
最近公司在做一些测试,属于简单重复劳动,一套做下来费神费力,又学不到什么东西,几乎没有收获。
因此写了一个python脚本自动去控制整个流程。
测试的流程是在一个Terminal软件里执行一系列命令(有一定规律性),然后对输出的结果做文字处理(提取关键信息,做数据统计、分析)。
文字处理用python好做,但是数据处理过程中其实是用一个前辈写的脚本软件实现的,所以有一丢丢麻烦的地方。
最后我写了三个程序来组成这个自动化脚本。
主程序会使用PyAutoGUI库来实现对鼠标和键盘的控制。
A子程序是一个命令生成器,在它里面定义一些规律性的东西,然后生成出一个cmd_list传回主程序。调试的时候直接运行子程序就能看到是否生成了预期的系列指令。
B子程序是中间信息处理。将主程序写在input文件里的内容提取出目标数据,存入另一个文档,用os库调用前辈的.exe档来执行中间处理。
具体来说,我的PyAutoGUI在程序开始运行时会要求用户进行两次移动鼠标的操作(坐标采集)。
采集到的坐标分别对应了Terminal软件和txt文档的编辑器。
正式开始运行之后,程序调用A的生成器获取命令列表,移动鼠标到Terminal去,选中这个Terminal,然后用键盘对它输入指令(整个命令列表)。
这里存在一个判断,如果当前输入的这条指令是一个很耗时的操作,那就time.sleep(5)这样等待一段时间。否则Terminal那边执行到一半,键盘就会开始下指令。相应地,输出的log信息也就会被打乱。
完成一套测试指令之后,PyAutoGUI会执行CTRL+C,去txt编辑器那边CTRL+V,然后保存这个log文件,交给B去做数据处理。
B完成处理的分析结果我是直接print到了console里。这样我对每轮的输出可以进行检查,然后手动写入excel文档里。
不过应该用csv库直接导出到csv更好。给代码增加一点健壮性,遇到log异常的时候直接重新进行测试就好了。
用到的第三方库:
- os
- time
- pyautogui
经验性的总结:
PyAutoGUI很好用,它还有官方中文说明文档:Doc PyAutoGUI
应该将程序模块化实现。对每个子程序都可以用
if __name__ == "__main__":
单独调试,很赞。
如果程序的功能相对固定,不需要经常修改的话,可以封装成exe,这样也方便同事使用(比如前辈给我的那个exe档)。例如可以参考:如何将python程序封装成exe可执行文件
后续如果要加csv输出的功能,参考:
13.1. csv — CSV File Reading and Writing
总结python对csv文件的操作
目前还存在另一个问题就是PyAutoGUI库还没支持多屏。双屏时它对相同坐标位于哪个屏幕可能会有些困扰。所以我跑脚本时都得把外接显示器拔掉。
这个问题只能等新版本的PyAutoGUI解决了。
Ello是我常用的一个社交自言自语平台。
我不想打扰朋友圈的时候就发在ello里。它的优势是文字内容不限长度,支持基础的排版(加粗、链接、tag、划去),允许发布后再次编辑,还支持图文混排。
以前它还有个优势是发图是不会被压缩,但现在也要压图了,而且没有针对长图优化(超长图片大概是起源于微博的中国特色?),所以有点烦。
ello另一个「卖点」是尊重个人信息的所有权。有比较丰富的隐私设置,号称绝不把用户数据出卖给广告商,还能方便地「带走」或者删除自己在这个平台上的数据。
我已经在ello上面产生了太多的内容(612 Posts),开始对这些信息的管理有所担忧。
所以今天试了下「带走」数据。
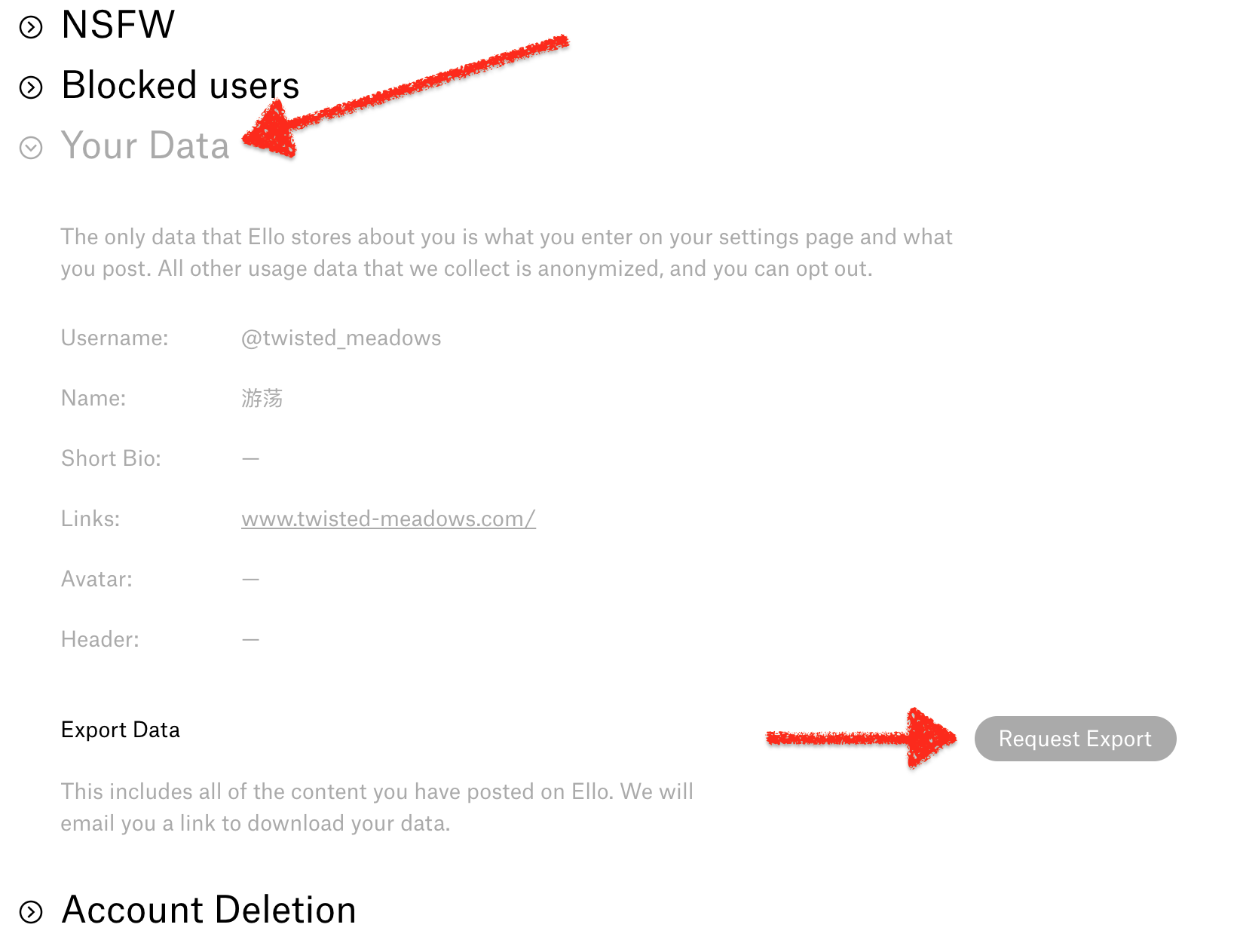
点击右上角头像,进入settings。往下翻,翻到Your Data标签,点开之后有Export Data选项,点申请。
然后ello就会把你的数据打包,下载链接发送到你的邮箱,24小时有效。
我跑到邮箱里一看,蒙蔽了,是个.json文件。
打开之后的体验如下:

好在我会python,对吧。
然后我就写了一个小的辅助程序。
它把json文件读入python,然后略去不重要的信息,只把post的内容和发布时间提取出来:
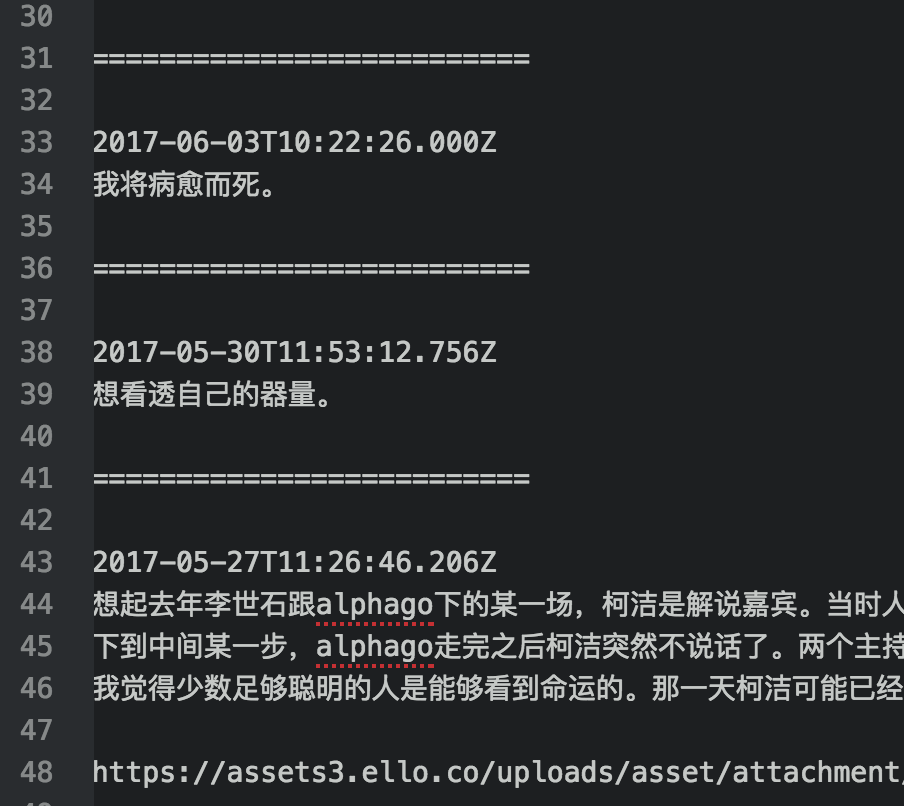
这对我来说就已经够用了。提取结果以文本形式输出到一个txt文件里方便以后查看。
图片以网址的方式给出。如果需要存图的话,随便写个小爬虫就能存下来了。
保存的post是按照最后编辑时间逆序(因为ello给的json里就是按这个顺序)。编辑顺序往往跟发布顺序不同。
发布时间已经从json里提取出来了,如有需要可以按发布时间再做一次排序。对我来说影响不大,我就没有加。
代码已放到GitHub:https://github.com/MamaShip/ElloExporter。
Telegram 为robot提供的 API
官方页面在这里:Telegram Bot API
而我使用的是一个叫 python-telegram-bot 的第三方库:https://github.com/python-telegram-bot/python-telegram-bot
开始用之前,你需要在telegram上找到@BotFather,根据它的指示新建一个机器人。完成之后你会得到一条这样的消息:
被我码掉的部分才是你需要的东西,也就是这个机器人的token。
这个第三方库通过 Updater 来基于token监听机器人的变化(接收到的信息)
from telegram.ext import Updater
updater = Updater(token='TOKEN')然后用 Dispatcher 对它做出响应
dispatcher = updater.dispatcher具体的做法是,建立一个handler,对特定的命令执行相应的函数:
from telegram.ext import CommandHandler
start_handler = CommandHandler('start', start)
dispatcher.add_handler(start_handler)上面的例子里,事先已经写好了一个start函数,(telegram里面大多数机器人都有 /start 命令)
当用户向机器人发送 /start 的时候,dispatcher 对’start’句柄调用start函数,传入 def start(bot, update) 的两个参数分别是 telegram.bot.Bot类 和 telegram.update.Update类。
我在函数内部执行以下代码:
print bot
print type(bot)
print update
print type(update)输出是:
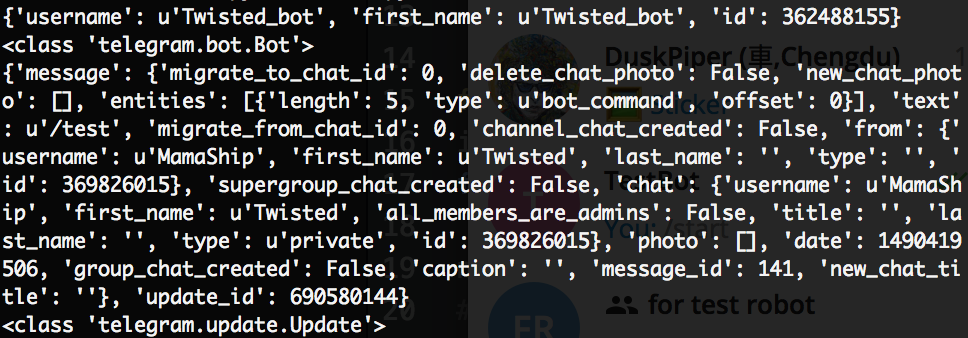
关于它们的属性和相关方法,可以参考官方文档。
python 操作 mysql
主要用到库 MySQLdb
大致是这么个操作方式:
# 打开数据库连接
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )# 使用cursor()方法获取操作游标
cursor = db.cursor()# 使用execute方法执行SQL语句
cursor.execute("SELECT VERSION()")# 使用 fetchone() 方法获取一条数据库。
data = cursor.fetchone()# 关闭数据库连接
db.close()
具体可以参考这个:python操作mysql数据库
有一点需要注意:执行INSERT这类修改数据库的操作之后,需要用 db.commit() 这句来提交事务,否则 mysql 那边不会真正的插入数据。(关于 autocommit 的探讨参见:Python 的 MySQLdb 模块插入数据失败与 autocommit(自动提交)的关系)
为robot创建一个mysql数据库
mysql很简单,具体过程不表。
创建之后,由于我们robot主要还是要说中文的,所以把数据库的字符集改成utf8:
show variables like 'character%';退出 mysql,去
vim /etc/mysql/my.cnf在各对应字段加入默认字符集设置:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
重启服务之后,再进入 mysql,你会看到还是有一点小问题:
mysql> show variables like ‘character%’;
+————————–+—————————-+
| Variable_name | Value |
+————————–+—————————-+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+————————–+—————————-+
8 rows in set (0.01 sec)
我试了试执行:
ALTER DATABASE `Robot` DEFAULT CHARACTER SET utf8;可行。
python的中文支持问题
python有很多方面都需要修改,才能正常处理中文字符串。在文档前加
# -*- coding: utf-8 -*-import sys
reload(sys)
sys.setdefaultencoding('utf-8')可以参考这篇文章:python2.7 查询mysql中文乱码问题
使python在后台运行
这篇文章提供了多种方案:python脚本后台运行
我为了调试方便,使用的是tmux:
1、启动tmux
在终端输入tmux即可启动
2、在tmux中启动程序
直接执行如下命令即可(脚本参考上面的): python test123.py
3、直接关闭ssh终端(比如putty上的关闭按钮)
4、重新ssh上去之后,执行如下命令:
tmux attach
现在可以看到python程序还在正常执行。
来测试我的机器人
Telegram上搜索 @Twisted_bot 来与他对话。
相关代码开源在:https://github.com/MamaShip/TwistedBot