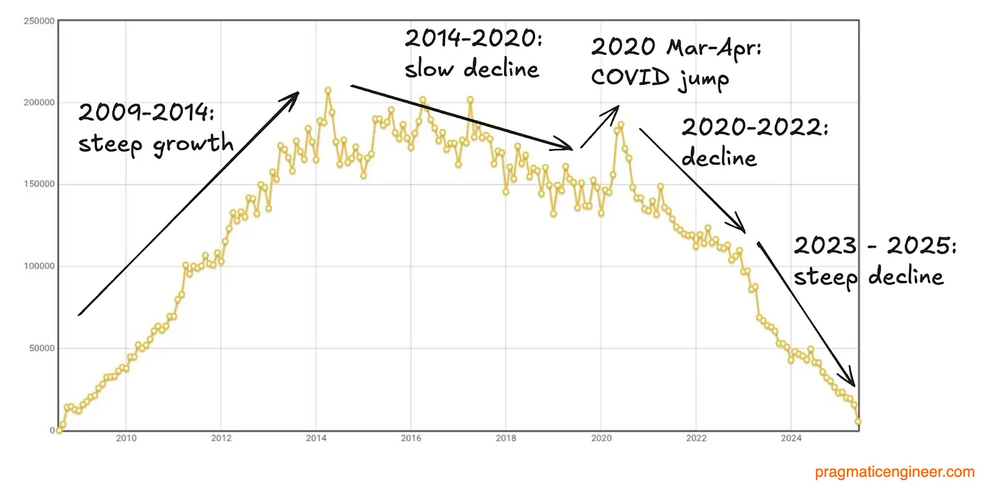
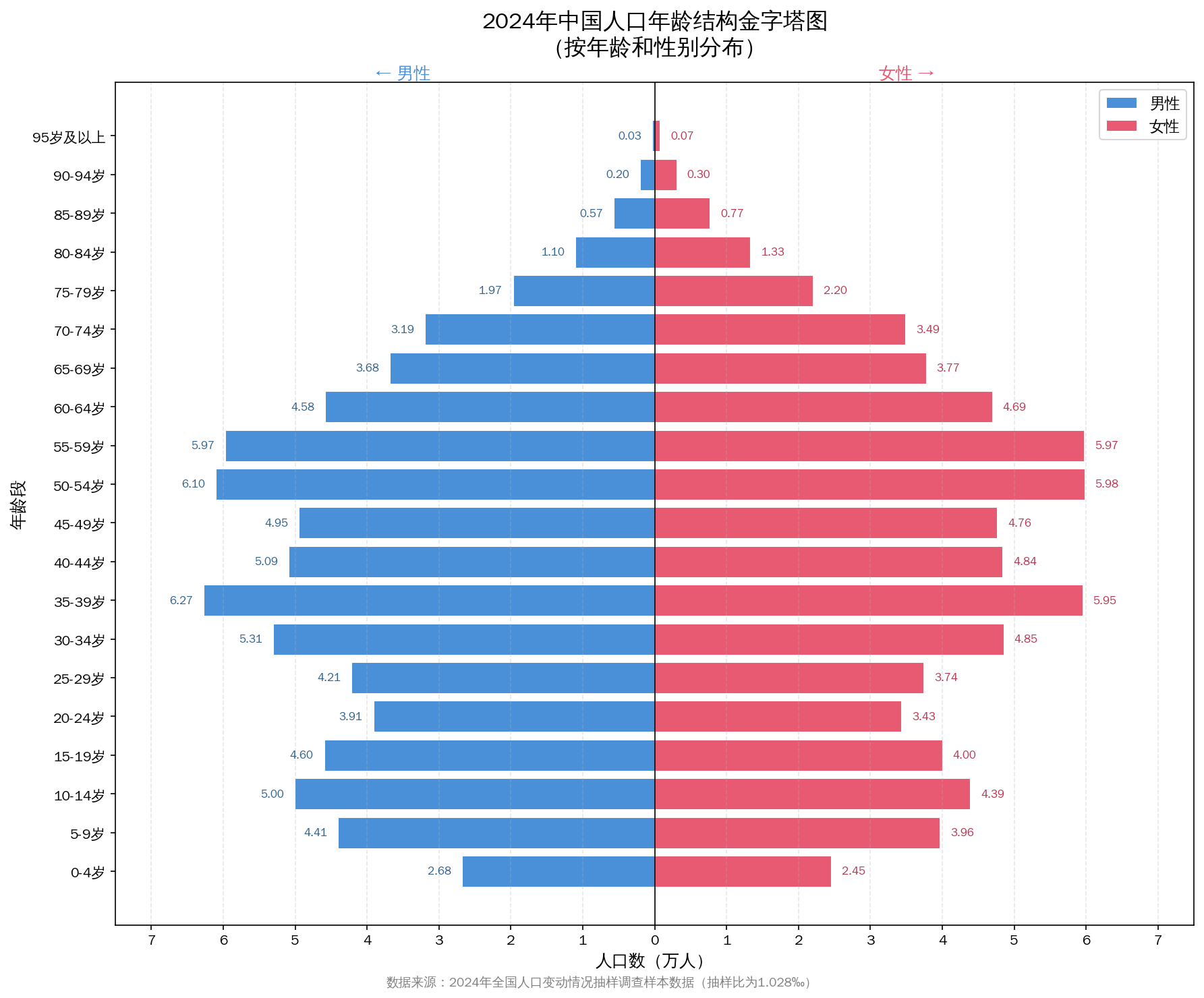
一、压缩现代性
1.1 理论来源
张庆燮(Chang Kyung-Sup) 提出的“压缩现代性”概念,最初用于分析韩国社会的急速转型。其核心含义是:一个社会在极短时间内经历了西方社会历经数百年才完成的经济、政治、社会与文化变迁,由此导致不同历史阶段的制度、价值与社会关系被压缩到同一时空中共存与碰撞。
压缩现代性不是简单的“加速发展”。加速意味着走得更快但路径相同;压缩意味着不同阶段的叠合——农业社会的制度遗产、工业化的组织逻辑、后工业社会的文化取向……并非依次替代,而是同时在场、相互纠缠。这种叠合构成了一种持久的社会结构特征。
1.2 压缩的多重维度
张庆燮的理论框架表明,压缩至少在以下四个维度上同时展开,每个维度都产生特定的结构后果:
| 维度 | 含义 | 在中国的典型表现 |
|---|---|---|
| 时间压缩 | 多个发展阶段被浓缩到极短的历史时段内同步发生 | 工业化、城市化、信息化、数字经济在三四十年内叠加推进 |
| 制度压缩 | 前现代、现代与后现代的制度安排并存,而非依次替代 | 家族伦理、计划经济遗产、市场机制、平台经济规则同时运作 |
| 文化压缩 | 传统价值观念与现代/后现代价值取向在同一社会中并行 | 儒家孝道、集体主义、消费主义、个体化取向在同一家庭内共存 |
| 空间压缩 | 不同发展阶段的社会形态在地理上毗邻共存 | 东部后工业城市与西部欠发达农业区并存于同一国家空间 |
这四重压缩相互交织,共同塑造了中国社会的基本结构特征。本文将依次展示:在这些压缩力量的作用下,中国形成了怎样的发展模式、制度安排、社会分配机制与家庭行为逻辑,以及它们如何构成一个相互关联的整体——压缩现代性社会结构。