在新冠疫情发生后2~3年,很多国家都已放开疫情管制,但中国政府仍然采用高压政策,通过「健康码」追踪人群流动,一旦发生传播就大规模封城,引起很多民众不满。这在社会各界产生什么样的反响?你怎么看待中国政府的选择?
MR-Tracker
项目地址: https://github.com/MamaShip/MR-Tracker
大家都知道基于 git commit 信息生成 ChangeLog 的工具,我之前也用过 git-chglog 等。
后来发现小团队内统一 commit 规范实在是费力不讨好……尤其有些提交很零碎,commit 信息作为 changelog 太琐碎,强制大家整理成完整提交再合入又显得不敏捷。
实际上,在 Github 上,自带的 Generate release note 功能就是基于 Pull Request 来分析的——它只记录真正合入主干的那笔改动,不会把粒度放到 commit 那么细。
所以我就自己写了个 Gitlab 上基于 Merge Request 生成 ChangeLog 的小工具。通过 gitlab API 获取 MR 信息,把版本(tag)间的改动创建成 changelog 。
市面上的显卡茫茫多,各型号的区别是什么?消费级和企业级显卡价格为什么差那么多?
显卡架构一代代更新,除了(运算)更快(功耗)更高(发热)更强,还有什么差异?有哪些理由支撑你一定要购买新一代架构的显卡?
这篇我们聊聊 Nvidia 显卡。以目前最常用的 Ampere 架构为例,揭秘 N 卡的内部细节。
抛开「算力」这种模糊的概念,用实打实的小学数学计算,来理解不同架构、型号之间的真正差异。
工作需要,最近在学高性能计算相关的知识。
这个领域,不涉足的时候觉得高深莫测,真正接触起来,不仅不神秘,而且十分有趣。
本文基于我对 LAFF-On Programming for High Performance (UTAustinX UT.PHP.16.01x)这门课的学习,结合个人在机器学习方面的经验总结形成,与大家分享。不当之处请指正。
如何实现高性能计算
从字面上来说,算得快就是高性能计算。
以此为定义,拥有超级计算机是做高性能计算的第一步,因为它从硬件性能上支持了「high performance」。
但显然,「硬件快」只是「high performance」的一个组成部分。在有限的硬件性能下,还有方法可以算得快。
例如分布式和并行化:把任务拆分成可以并行执行的多个部分,用多台机器同步运算,是个好主意。
或者给机器上插很多块显卡(GPU),利用显卡的并行计算能力,来做异构计算(由CPU执行串行部分,GPU执行并行部分)。
——如果只有一台机器,没有显卡,机器的性能也很一般呢?
本文接下来要讨论的,就是在常规架构的普通计算机单机上,如何做高性能计算编程。
特殊地,我们讨论最常用的一种运算:矩阵乘法。我们将会看到,它在时下流行的神经网络中如何被广泛应用,又是如何被最高效地实现为C代码。
本文记录于2021年初。不满于网络上的资料大多过时和有瑕疵,重新整理 Ubuntu 环境下配置 CUDA 开发套件的步骤。
- 本文介绍的步骤主要面向 CUDA 相关的机器学习开发环境配置。所以它包含 CUDA、cuDNN、TensorRT、onnx。如果你不需要其中某些组件,直接跳过即可。
- 本文涉及的版本信息:Ubuntu 18.04、CUDA 10.2、cuDNN v8.0.5、TensorRT 7.1 GA。请根据你自己的需要选择恰当的版本,唯一注意的是:这几个组件之间的版本必须严格对应,请跟自己的团队确认好版本之后再执行安装,否则会遇到很多版本兼容性问题。
今年初,有感于微信公众号平台删帖效率,打算写一个自动检查文章是否被删的机器人。
并不想弄成爬虫,只想关注我和小伙伴们所接触的领域里的信息审查状况。就把它设计成了「被动接受观察目标,定期观察和备份文章,检查到文章失效通知登记者」的系统。
我在自己的 mac 上使用 ssh 连接到远端 Linux 服务器,除非网络波动,一般不会出现连接断开(输入无响应)的问题。
但在 Windows 上,使用 PowerShell 自带的 ssh,连接到远端 Linux 服务器,很短一段时间不操作,就会发生断开。
这个现象应该是跟服务器端设置有关,但我不想修改服务器设置(用户无操作自动断开是个好特性)。既然 Mac 上可以不断开,win 上应该也可以在客户端设置上避免频繁断开。

这是一篇 Neural Style Transfer 的简要介绍。一方面是我的学习笔记,另一方面想向大家介绍这种有趣的神经网络应用。
我不知道是否该翻译为「风格迁移神经网络」。但它的英文原名清晰地给出了3个信息:
Neural-神经 Style-风格 Transfer-传输/转换/迁移
这也是它最核心的3个属性。
Neural Style Transfer能做什么呢,就是学习一种图像的风格,然后把别的图像转换为这种风格。像下图所示:

看了HBO的《切尔诺贝利》迷你剧。其实有明显的歧视社会主义的色彩啦,解读方式不能不说是带有某种偏见。不过影响不大,毕竟令人震惊的事实就是无可撼动。
像武汉一样,切尔诺贝利核电站事故的第一瞬间,政府反应就是封城,切断外界联络。威权国家的这种思维惯性还是让人细思恐极。它总是轻易地牺牲掉一大群人。
这种理念跟西方的个体自由文化格格不入。可以想见,西方看待这次武汉,也跟看待切尔诺贝利一样——他们根本不相信你对外发布的信息,因为你的做法(封城)就不是一个符合他们价值观的行为。中国政府的操作已经把自己标榜到文化对立面,是不值得信任的。
近期我的PC遇到个问题,我的NS Pro手柄,在一段时间没有连接电脑后,再想连接时,无法顺利连接了。
具体来说,Pro手柄因为默认是Nintendo Switch的手柄,所以在插上NS后会自动配对连接。那么下次你想用它连接电脑蓝牙来玩PC游戏时,就需要重新配对了。
重新配对前,需要删掉前一次配对的信息,也就是在系统的显示蓝牙设备列表里,删掉Pro手柄的已配对项。
通常情况下这一切都很顺利,但这次遇到了bug:无法删除该蓝牙设备。
具体表现为:已配对项右下有删除键,可以点击,但点击之后无反应。
我check了网上能搜到的信息,包括微软官方这篇: https://answers.microsoft.com/zh-hans/windows/forum/all/win10%E8%93%9D%E7%89%99%E8%AE%BE%E5%A4%87%E6%97%A0/dd641a9b-ca95-491a-8cd9-90747b36fe2c
但微软的bug令人惊叹,相关注册表项禁止我修改,说我没有权限。我作为这台电脑的owner,却没有权限修改它。
最终找到的可行解决方案是这篇,转载其内容存档如下:
题记
Win10 很多 Bug
问题描述
Win10 与蓝牙设备(比如蓝牙键盘,蓝牙音箱)出现了无法连接的情况,本来打算删除已配对的设备,再重新配对连接。但 Win10 很多 Bug 呢,删除设备后重启蓝牙,那些原本被删除的设备又回来了,是的,全都回来了。
解决方法
尝试了很多方法,包括网上流传的打开飞行模式,在控制面板里的设备与打印机里删除设备等等,均无效。
后来的一切,是缘份了。和你恰好在浏览这篇文章道理相似。
原帖如下,链接:https://www.tenforums.com/drivers-hardware/22049-how-completely-remove-bluetooth-device-win-10-a.html
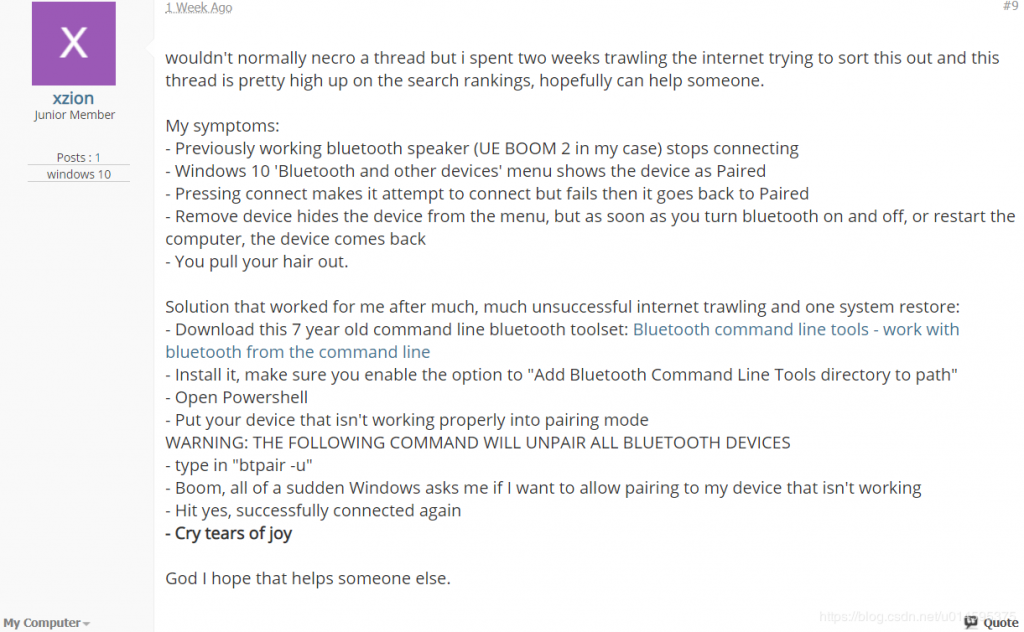
具体解决方法,翻译过来就是:
下载 修复工具,一路默认选项完成安装。防止链接失效,附上 百度网盘链接
打开 Powershell,命令行输入 btpair -u,回车执行
等待,会发现已配对的蓝牙设备 终于 成功 彻底 被删除了
喜极而泣
————————————————
版权声明:本文为CSDN博主「一木扶苏」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u014595375/article/details/85730427
百度网盘下载连接备份如下:
链接: https://pan.baidu.com/s/1tghoYBZxkzxqwvxPYtVumg 提取码: si23