市面上的显卡茫茫多,各型号的区别是什么?消费级和企业级显卡价格为什么差那么多?
显卡架构一代代更新,除了(运算)更快(功耗)更高(发热)更强,还有什么差异?有哪些理由支撑你一定要购买新一代架构的显卡?
这篇我们聊聊 Nvidia 显卡。以目前最常用的 Ampere 架构为例,揭秘 N 卡的内部细节。
抛开「算力」这种模糊的概念,用实打实的小学数学计算,来理解不同架构、型号之间的真正差异。
详解 GPU 核心
开始之前,先回顾下 CPU。什么是 CPU 核心?

大家对 CPU 比较了解。都知道主板上哪个芯片是 CPU:作为中央处理器,它有专门的插槽、夹具、散热器,主板上的大多数元件都是围绕 CPU 来构建的,就是要为它服务。
把声卡、显卡这些不必要的东西放到一边,如果我们只搭建一个最小系统——你会意识到,所谓的「电脑」,仅仅是一个:可以处理一切运算的 CPU,加上为这个 CPU 服务的存储装置(内存、硬盘)和通信组件(PCIE总线、USB接口等等)
CPU 的一个核心(Core)封装了几乎所有的功能:
– 算术逻辑单元 ALU
– 浮点处理单元 FPU
– 地址生成单元 AGU
– 内存管理单元 MMU
– ……
CPU 一个 core 就可以处理计算机的所有操作。
后来出现的多核处理器,也只是对这一个 core 的简单复制、集成封装(如果我们忽略掉核与核之间的交互)。
GPU Core
显卡虽然是一大块卡,但它真正执行运算的部分只是一枚和 CPU 一样大小的芯片——显卡核心;显卡 PCB 上其他组件,都是为它提供电源、通信、存储功能的。
这个小芯片承担着与 CPU 不同的定位和功能,芯片设计思路也完全不同。这就导致,我们谈论 GPU 时,所说的 Core,完全不是 CPU 上那个意思。
作为辅助 CPU 执行计算的周边器件,它不需要承担那些系统管理、调度的功能,完全专注于使用(大量的)小核心并行化地执行基础运算(通常都有数千个核心同时执行)。—— GPU Core 小而且多,这是我们的初步印象。
Nvidia – CUDA Core
N 卡上,经常提到的概念是 CUDA Core。英伟达倾向于用最小的运算单元表示自己的运算能力,CUDA Core 指的是一个执行基础运算的处理元件。最早的时候,这个「基础组件」类似于 CPU 中负责各种数值计算的那个 core,能做很多通用运算。
但后来就不一样了,例如整型计算和浮点型计算单元的数量不一样了。CUDA Core 不再能 1:1 地对应上这些小运算单元。它的定义就开始变化:有时2个 CUDA Core 才能凑出1个整型运算单元。
所以 CUDA Core 的定义其实是复杂而且变化的。你不能单纯用 CUDA Core 的数量来跨代际比较显卡性能(因为它在两代显卡中的定义都不同)。
由于 CUDA Core 根本就是为了方便商业营销而创造的概念,英伟达喜欢将其称为「用于营销目的」的核心。
随着架构的更替,经过一代又一代的演变……
现在 Ampere 架构上所说的 CUDA Core(的数量),对应的其实是 FP32 计算单元(的数量)——你可以认为它对应了 CPU 中计算浮点运算的那个小组件(FPU),但这个对应也是不恰当的,我们会在后面看到更多细节。
AMD – Compute Unit
AMD 倾向于简化整个模型,用 CU 来讨论他们的显卡核心数量。Compute Unit 指的是一组执行运算的元件的集群(cluster),它里面有大量更小的计算单元。
由于技术路线和优势不同,AMD 更在乎自己的总线技术(例如 Infinity Cache)和集群结构,自然也倾向于以 CU 数量来讨论显卡性能。CU 不会具体对应到计算单元的数量,而只是跟缓存、总线结构有关。
CU 在概念上更接近 Nvidia 的 SM。所以千万不要拿 A 卡的 CU 与 N 卡的 CUDA Core 相比,是两个完全错位的概念。
GPU Core
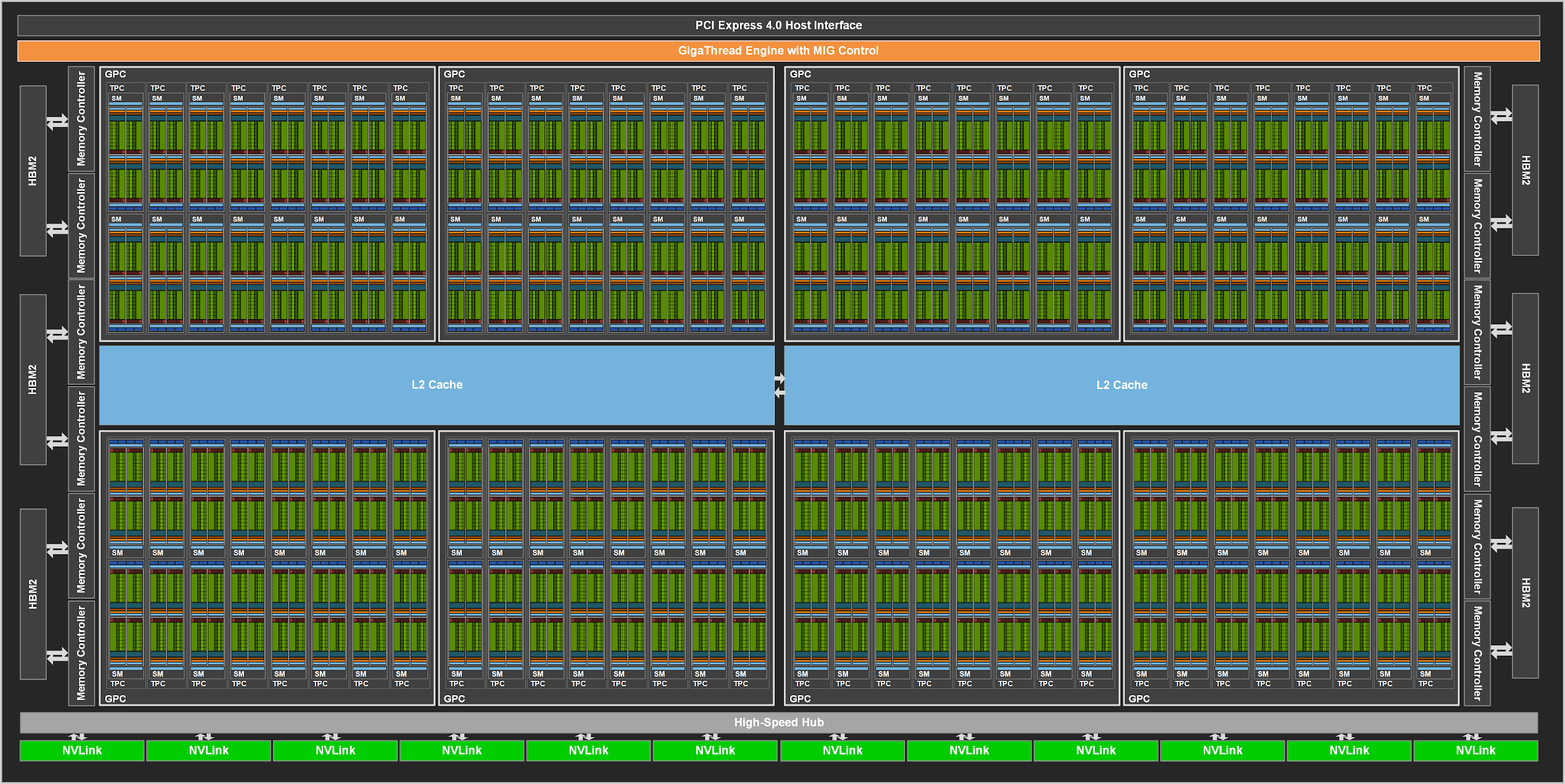
现在我们把 GPU 芯片打开,看看内部结构。上图是 Ampere 架构最强显卡 A100 的内部架构。
它有 128 个 SM(Streaming Multiprocessor,流式多处理器),密密麻麻地排布在中间蓝色的 L2 Cache 两侧。关注 SM 这个概念,它在 N 卡架构中非常重要,N 卡的多核并行化就是靠平行布置大量的 SM 来实现的。
SM(Streaming Multiprocessor)
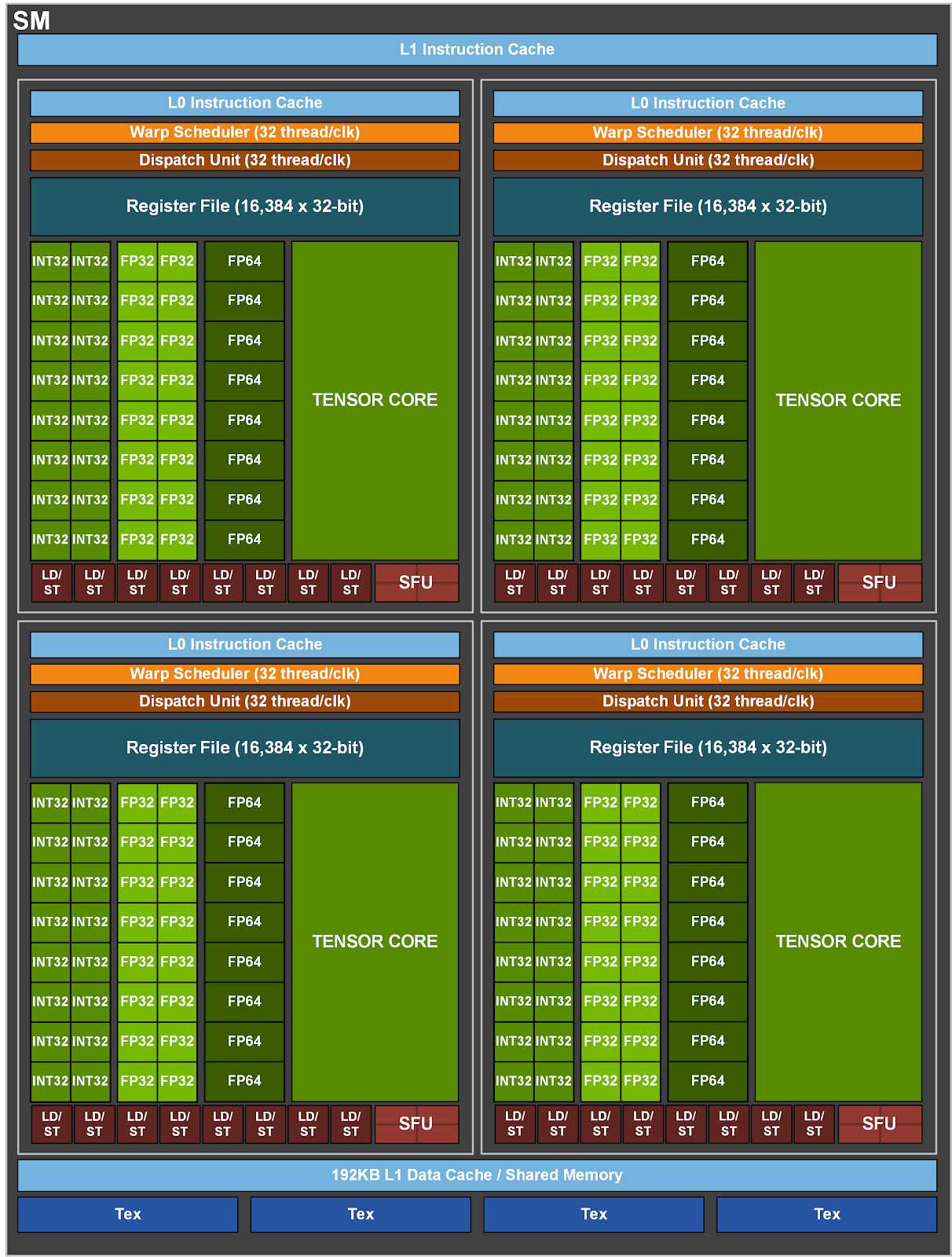
- 每个 SM 里面有 4 个 Warp Scheduler(对应划分出 4 个 processing blocks)
- 每个 Warp(最多)同时执行 32 个 thread
- 这就实现了 SIMT – 单指令多线程
- L1 Cache 对 SM 内的 threads 是共用的
- 对不同 SM 的 L1 Cache,没有数据一致性
[补充]:如果你不了解 Warp(线程束),它是 Nvidia GPU 上最小的调度单元。在 GPU 上,一批执行相同任务的线程被定义为一个 Warp 来下发指令,只需要一条指令,Warp 内线程并行执行。
基础组件:INT32、FP32、SFU
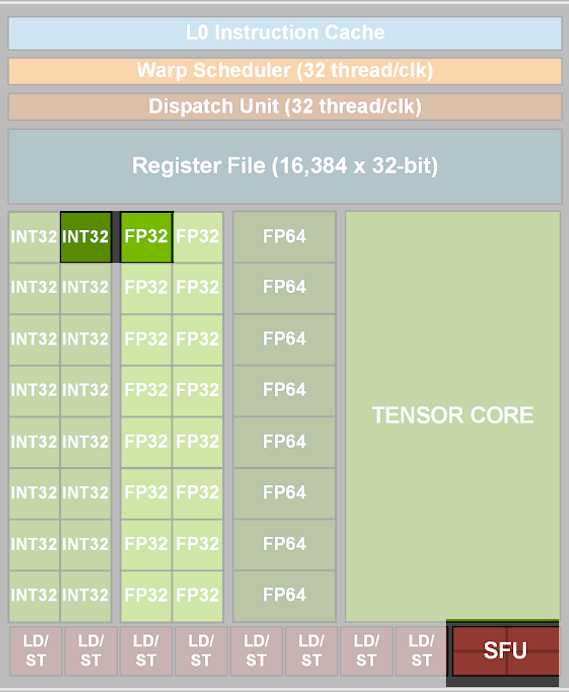
让我们关注图上高亮的区域——
早期的 GPU 架构,仅提供最基础的 core:
32 位的整数和浮点数运算
图上的 INT32 是负责32位整型运算的器件。FP32 负责32位浮点型计算。
另外,作为图形卡,GPU 要负责电脑画面的渲染显示,所以专门配置了 SFU,用于运算超越函数(sin、cos、exp、log……)。
这是因为 3D 游戏中所有的立体形状其实都是由微小的三角形拼接而来,而显卡要计算的就是这些三角形的平移、旋转等等。
FP64 的加入

再后来,由于科学问题的求解需要大规模并行计算能力,很多科学家使用 GPU 来进行科学计算。
这种场景中,经常用到高精度的数据类型。为了增强科学计算能力,Nvidia 给他们的 GPU 新增了 DPU(FP64),负责64位浮点型的计算。
注意,FP32 是可以被用来计算 64 位浮点的,只是要慢很多,它在硬件上只能算 32 位,所以 64 位的计算被拆成复杂的子步骤,再合并出结果。
具体来说:FP32 需要二十多个时钟周期来执行一次 64 位浮点运算。FP64 可以直接运算,节省十几倍的时间。

但是浮点型计算是挺复杂的一个电路,随着计算位数的增加,电路面积呈指数级增长。你从架构图上也可以看到,FP64 占的面积比 FP32 大很多。
不过没关系,FP64 这么强,1个顶10个,所以不用跟 FP32 按 1:1 数量配置。
在 Ampere 架构上,Nvidia 选择给每 2 个 CUDA Core 搭配一个 FP64。(从 Kepler 架构开始,CUDA Core 就不再能与底层组件的数量一一对应了,当时 FP32 与 FP64 的数量是 3:1)
自 FP64 加入后的每代显卡,FP32 和 FP64 的数量比例都在调整——Nvidia也在寻找面积与性能平衡的方案,以讨好自己的所有客户。
超级大核 Tensor Core

再往后,机器学习、神经网络的时代到来了。在这种应用场景下,矩阵运算的计算量非常大……那就干脆……再来个 Tensor Core,专门算矩阵!

上图是 Volta 架构上 Tensor Core 的工作原理示意。
Tensor Core 有着专门设计的硬件结构,可以把整个矩阵都载入寄存器中批量运算,有十几倍的效率提升。这简直是机器学习神器——自 Volta 架构发布以来,奠定了 N 卡在机器学习领域的江湖地位。
后来的每一代架构,除了制程上的进步,Nvidia 也不遗余力地更新着他们的 Tensor Core:

第 2 代,Turing 版本,Tensor Core 支持更多的运算类型:
– FP32
– FP16(半精度浮点)
– INT8
– INT4
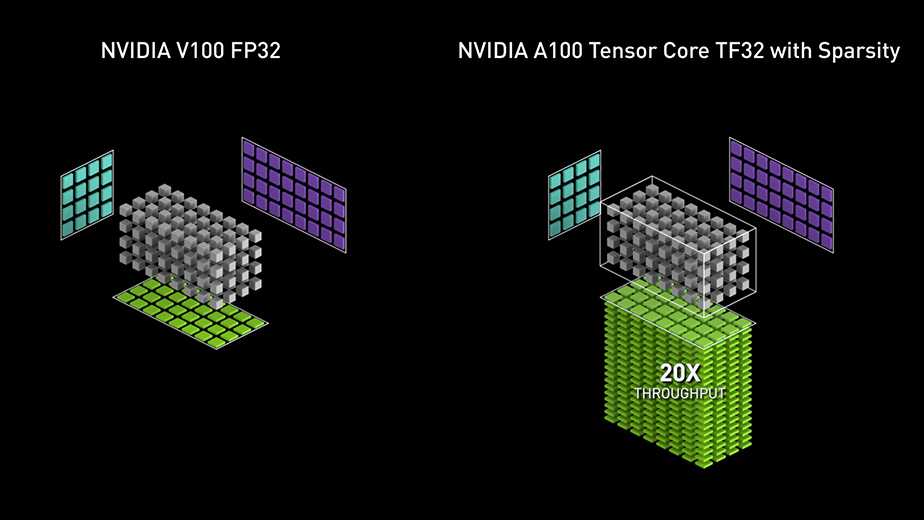
第 3 代,Ampere 版本,新增支持数据类型:TF32 和 FP64。
并且支持稀疏矩阵运算,能够忽略矩阵中值为 0 的位置,跳过它们的计算,比不支持稀疏矩阵的版本快了 20 倍。
(当然,稀疏矩阵特性要求神经网络在训练时就把参数训练成稀疏的,需要额外的处理步骤)

即将到来的第 4 代,Hopper 版本,为提升 Transformer 网络的性能,增加了 FP8 数据类型支持。
并且把 Tensor Core 设计得更大了——它现在可以一次性 load 更大的矩阵进去执行运算。
同时得益于 Hopper 上更高的运算频率,和额外的 Tensor Memory Accelerator,在所有类型的数据上都获得 3 倍的吞吐量提升。
整合起来
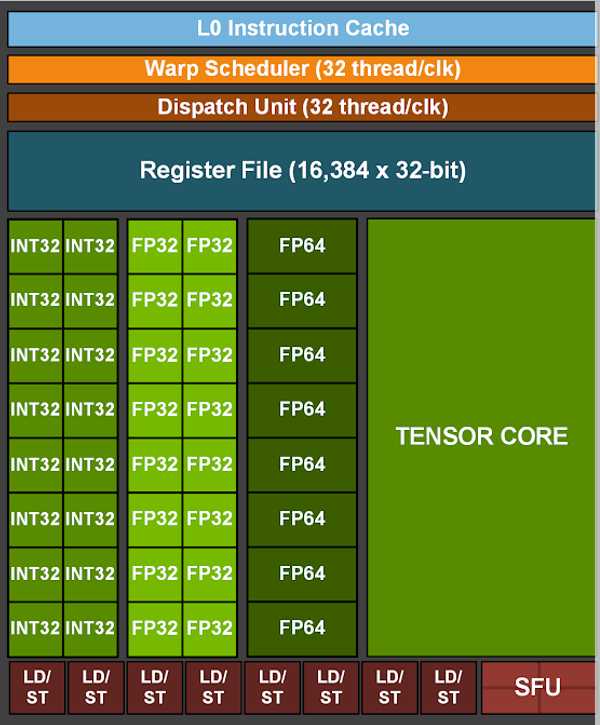
把上面提到的这些器件,成倍地设计出来,由同一个 Scheduler 调度(Warp Scheduler 和 Dispatch Unit)。
再加上辅助运算的周边电路:
– 寄存器(Register File)
– 数据加载、存储队列(LD/ST)
– 指令缓存(L0 Instruction Cache)
这就成了我们最开始看到的 Ampere SM 架构图:
每个 SM 包含 4 个 processing blocks,它们共用这个 SM 的 L1 Instruction Cache(一级指令缓存)、L1 Data Cache(一级数据缓存)、Tex(纹理缓存,Texture cache)
把大量这样的 SM 排布在一起,将它们连接在 L2 Cache 和全局的调度器(GigaThread Engine)上,再为整张芯片设置与外部通信的线路——这就是用于 Data Center 的安培架构显示核心 GA100 的所有组成成分。

补充:RT Core(Ray Tracing)
游戏玩家一定会问,等等!我的光追核心呢?
事实上,Data Center 版本的 N 卡核心是不带 RT Core 的,只有后来出的消费级显卡才为光线追踪运算添加了 RT Cores——也就是编号为 GA10X 的那些核心,GA102、GA104、GA106…及它们的变种。

因为片上空间有限,每个 SM 里面只有1个光追核心(为此还砍掉了大部分的 FP64)。光是这样就已经极大地提升了游戏渲染效率,看看官方公布的延迟比较:
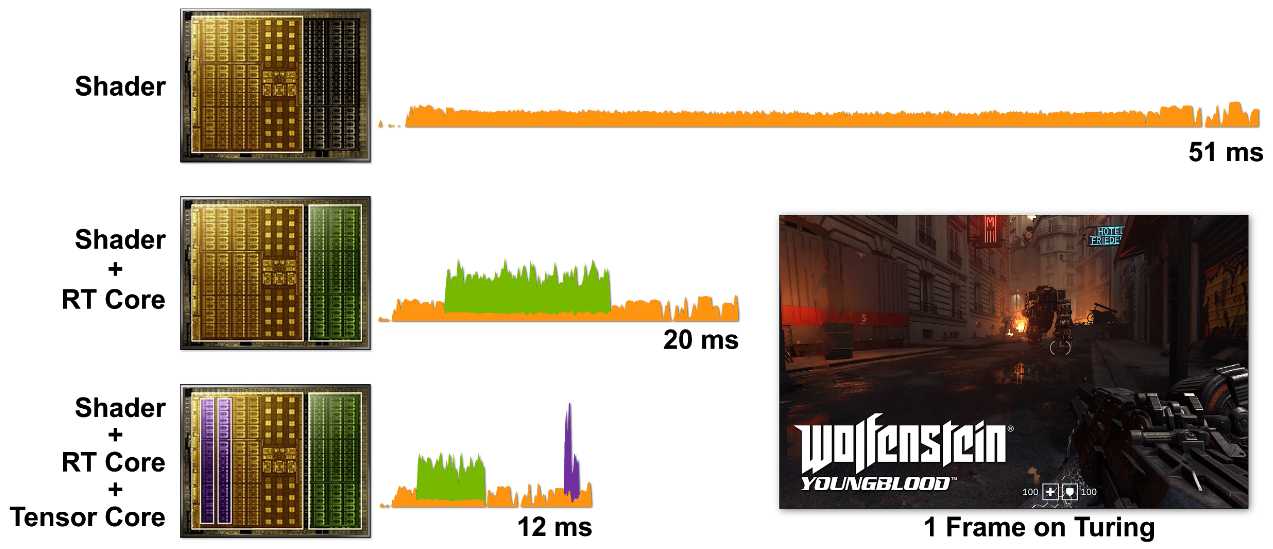
图示为 Turing 架构。在 Ampere 架构上,升级过的 RT Cores 和 Tensor Cores 配合起来提升还要更多。
N 卡的架构
了解了显卡的构成细节,怎么来解读一块显卡呢?任意两块卡怎么比较性能?
应用场景不同,用到的运算功能也不同,英伟达官方公布的所谓 xx TFLOPS 显然不足以让人信服。
Nvidia 架构变迁
实际上每代显卡的变化都是非常大的,商业公司有时为了竞争市场,会做出激进的设计变化。
而 Nvidia 又包装出了 CUDA Core 这种迷惑的营销概念,它在每代显卡上含义都不同,你要是光知道去比较 CUDA Core 数量,那就正好被 Nvidia 骗到了。
下表是我自己整理的显卡架构信息(以每代架构中最强显卡的参数为代表)
| 计算能力 | 架构 | 发布年代 | Cores/SM | 总 SM 数 | CUDA Cores |
L1 Cache (KB) |
L2 Cache (KB) |
|---|---|---|---|---|---|---|---|
| 1.0 | Tesla | ||||||
| 2.0 | Fermi | 2009 | 32 | 16 SM | 512 | 48 | 768 |
| 3.0 | Kepler | 2012 | 192 | 15 SMX | 2880 | 48 | 1536 |
| 4.0 | – | ||||||
| 5.0 | Maxwell | 2014 | 128 | 24 SMM | 3072 | 96 | 2048 |
| 6.0 | Pascal | 2016 | 64 | 60 SM | 3840 | 64 | 4096 |
| 7.0 | Volta | 2018 | 64 8 个 Tensor Core |
80 SM | 5120 | 与共享内存共用 128 (最多 96) |
6144 |
| 7.5 | Turing | 2018 | 64 8 个 Tensor Core |
72 SM | 4608 | 与共享内存共用 128 (最多 96) |
6144 |
| 8.0 | Ampere | 2020 | 64 4 个 Tensor Core |
108 SM | 6912 | 与共享内存共用 192 (最多 164) |
40960 |
| 9.0 | Hopper | 2022 | 128 4 个 Tensor Core |
144 SM | 18432 | 与共享内存共用 256 | 61440 |
[补充]:从 Turing 开始出现了半代计算能力的区别,实际上 Turing(7.5) 是 Volta(7.0) 的小改款。(Turing 架构 = Volta 架构 – FP64 + RT Cores)
在 Ampere 这一代上也有这种区别,计算能力 8.0 对应最早的企业级显卡核心(GA100),8.6 对应之后的消费级核心(GA102、GA104、GA106、GA107),虽然 8.6 没有获得一个额外的架构命名。
Hopper 架构上,不出意外也会有半代计算能力的区别——这实质上是 Data Center 核心和消费级核心的区别。
上表中值得注意的信息:
- 每代卡的 SM 都有较大设计改动,甚至有时连名字都改了(SMX、SMM),这是影响性能细节的关键
- 尽可能多的 SM 数和 Cache 容量是性能提升的核心要素。但是受限于芯片面积,厂商无法简单增加这两者。反而每隔几年的制程工艺提升总会带来 SM 和 Cache 的增加。
- SM 内的 FP32 数量曾在 Kepler 架构上被设计得很高,但是缓存不够大导致每个 FP32 能用的缓存很小,性能根本发挥不出来。所以 Nvidia 后来又逐渐调降了 SM 内 FP32 的数量。
你能从架构变迁中感受到厂商的努力:在芯片面积有限、功耗/散热有限的情况下,不断调整各种组件的配置比例,凭借制程工艺的提升,寻求一个客群最大化的较优解(还要尽可能碾压友商)。
相同架构下各型号的区别
芯片设计和验证的成本很高,一次流片就要花费上千万。何况 Nvidia 这种追逐最新工艺最新制程的企业。
为了节省研发成本,通常情况下,每一代架构,SM 的设计只有 1 版。
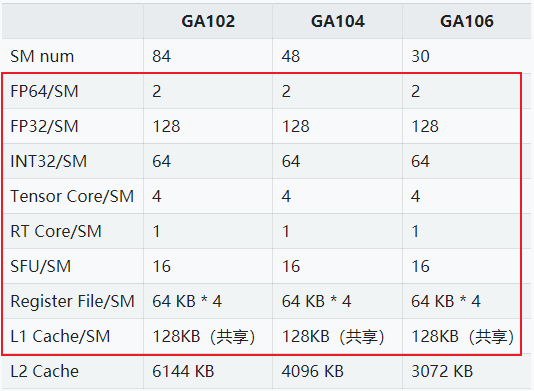
上表列出 Ampere 架构下 3 个典型的核心型号。它们的 SM 数量不同、L2 Cache 大小不同,但 SM 内部的配置(红框区域)是完全相同的。
它们共用了相同的设计,仅仅通过调整 SM 数量来影响性能和功耗,给客户出货不同的显卡型号。
而每张卡上有多少个 CUDA Core,也是由 SM 数量决定的。例如 Ampere 这一代每个 SM 里面有 128 个 FP32(前面提过 Nvidia 目前用 FP32 数量作为 CUDA Core 数量),所以任何型号的 Ampere 显卡 CUDA Core 数量都是 128 的整数倍。——如果不知道某张卡有多少 SM,用 CUDA Core 数量除以 128 就能得到它的 SM 数。
使用这3个核心的典型显卡:
- GA102 :3080\3080Ti\3090\A5000\A6000
- GA104 :3060Ti\3070\3070Ti\A4000
- GA106 :3060\3050Ti\A2000
也就是说,3080 和 3090,它们显卡中央那块小芯片是同一型号的——GA102。
既然是相同显卡核心,为什么这些卡会有性能差异呢?
因为出货给你的时候,GA102 被锁住了一部分 SM,使得用户真正可用的 SM 数量是不同的。这相当于厂商通过硬件手段限制了核心的性能,同时也降低了显卡的功耗。
Ampere 常用显卡的可用 SM 数量
| 显卡型号 | 3060 | 3060Ti | 3070 | 3070Ti | 3080 | 3080Ti | 3090 | 3090Ti |
|---|---|---|---|---|---|---|---|---|
| SM 数量 | 28 | 38 | 46 | 48 | 68 | 80 | 82 | 84 |
| 显存 | 12 GB | 8 GB | 8 GB | 8 GB | 10 GB | 12 GB | 24 GB | 24 GB |
从我整理的表格里你可以看到,所谓「老黄精准的刀法」,其实就是通过限制用户可用的 SM 数量,再搭配上不同的显存容量,来实现不同型号的「精准定位」——也就是价格歧视啦。
半导体良率问题
但厂商这么做的深层原因还是来自半导体行业的固有特性——芯片刻蚀是一项很容易出错的工作。
尤其在制程工艺逐步逼近极限的今天,已经很难做到在几纳米间毫厘不差。即使技术最先进的台积电,也不能保证大多数芯片是完美的。

半导体厂商通常不会把芯片设计成一点缺陷都不允许——那样会导致良品率极低。而是设计成:片上各区域分别独立,可以通过开关关闭。
这样,例如 GA102 被设计成由 84 个 SM 组成,某张芯片在光刻过程中刻坏了其中 2 个 SM,只有 82 个可用 SM,厂商就在出厂前,通过写固件的方式关闭那 2 个坏区块的电路(切断电路,无视内部短路或开路),让整张芯片在只有 82 个可用 SM 的情况下也能工作。
只要从设计层面预先做好这个逻辑,出厂前扫描一遍,通过固件配置关掉坏区块,就能充分利用这些不完美、但也不差的芯片。
[补充]:硬件爱好者会说某些芯片「体质好」,所谓的体质好,就是指芯片刻蚀的质量高。使它可以工作在更高频率下也不出错。
同样的情况放在显卡核心上,出厂时芯片检测筛选出那些质量高的核心,会被用在企业级显卡上,这样它们可以在更低功耗、更高频率下,持久稳定地运行。所以会卖得更贵。消费级显卡则不做持久运行的保证,随时可能因为电路异常而发生运算错误(你的蓝屏也许不是因为 Windows 系统 bug,而是显卡在一次运算中发生了致命错误)。
所有的 GA102 都是按原设计图生产的,唯出厂前芯片检查时,会根据测试结果,将其分为三六九等,分别出货给 3080、3080Ti、3090 显卡的产品线。
跟上面的表格对照,你就知道,这块 82 SM 的芯片,将被用在一张 3090 显卡上,以 3090 的形态出货。若生产过程中坏掉的 SM 更多,可能就是作为 3080Ti 或 3080 来出货。
结论
综上,比较同一代架构的显卡时,直接看它们有多少可用 SM 数量,本质计算能力与这个 SM 数量线性相关。
比较不同架构的显卡,需要去找它们的官方架构白皮书,仔细研究 SM 构成差异,看里面具体的计算组件数量(再乘以 SM 数量来估算总体性能)——如果你的使用需求是整型运算,就关注 INT32 数量;如果是单精度浮点型,关注 FP32;如果是高精度的科学运算,FP64.
再考虑其它特殊因素的影响:深度学习通常会用到 Tensor Core、玩游戏通常会用到 RT Core……
关注你的使用场景要求多大的显存(超出使用需求的那部分容量会被浪费掉,但是不满足容量需求的卡直接就是不可用的)
并且不要忘了,除计算单元的数量决定计算能力,芯片的工作频率也对整体有一个加成。更不能忽略 IO 的影响:各级缓存的大小也会限制调度性能,同时,芯片的显存位宽对 IO 效率有加成作用。
(显卡瓶颈分析也许会另开文章解析)
好,你已经是精通 Nvidia 显卡的硬件选型大师了!

Comments
第 2 代,Turing 版本,Tensor Core 支持更多的运算类型:
– FP32
– FP16(半精度浮点)
– INT8
– INT4
这里 Tensor Core 应该是不支持 FP32 的。
Author
你可以看下文末参考链接里官方的 Tensor Core 页面。
从我司的使用经验上,Turing 这一代的 Tensor Core 无疑是支持 FP32 的:
相同 SM 数量的 Turing 和 Ampere 显卡,FP32 的数量相差一倍。但是在我们的使用场景下(有很多矩阵运算),Turing 卡只比 Ampere 慢了 10%。
唯一的解释就是 Tensor Core 加速了 Turing 卡的运算,因为 Turing 的 SM 里面有两个 Tensor Core,而 Ampere SM 只有 1 个。
在炼丹厂呆久了你也是体系结构专家了
Author
🤣 我们不炼丹,我们是讲科学的(严肃
在显卡架构信息这种表格中,为什么8.0的SM数量是108,看文章其他地方描述8.0代表Ampere 最强A100,有128个SM。
Author
A100 的官方白皮书里可以看到:
The full implementation of the GA100 GPU includes the following units:
● 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
● 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
● 4 Third-generation Tensor Cores/SM, 512 Third-generation Tensor Cores per full GPU
● 6 HBM2 stacks, 12 512-bit Memory Controllers
The NVIDIA A100 Tensor Core GPU implementation of the GA100 GPU includes the following units:
● 7 GPCs, 7 or 8 TPCs/GPC, 2 SMs/TPC, up to 16 SMs/GPC, 108 SMs
● 64 FP32 CUDA Cores/SM, 6912 FP32 CUDA Cores per GPU
● 4 Third-generation Tensor Cores/SM, 432 Third-generation Tensor Cores per GPU
● 5 HBM2 stacks, 10 512-bit Memory Controllers
似乎满血版的 GA100 芯片有 128 SMs,但实际出货的 A100 显卡只有 108 SMs。
你可以结合文章内容理解一下他们锁 SM 的意图。
文章内应该是表述有一些偏差,把 GA100 芯片说成了 A100 显卡
Ada Lovelace架构 和上述的架构是什么关系了?
Author
Ada Lovelace 和 Hopper 是同一代架构,只是分别供货给超算领域和消费级市场。
就像文中说的,消费级芯片会带有 RT Core,这些处理器在 Data Center 是用不上的。
所以是同一代制程工艺、架构设计,微调衍生出来的2个变种。